目次
はじめに
どうも、最近ゲームにドはまり中のしがないITエンジニアです。
スプラトゥーン3をやっているのだが、初心者でもプレイできるのは有難い。
BFやCODなどのガチのシューティングゲームは、
射程が長すぎて初心者がただの的になるのがいただけない。
その点、スプラトゥーンは射程がかなり短いため、
アウトレンジから一方的にボコされるということは少ない。
また、相手を倒すことが直接的な勝因ではないため、
塗りに専念してチームに貢献できる点も初心者に優しい点と言えるだろう。
まったく良いゲームを作ってくれたものである。

さて、そろそろ本題を進めるとしよう。
今回話す内容は文字コードについての話である。
筆者はEDIの運用の都合上、Shift-JISやUTF-8、果てはEBCDICなど様々な文字コードに触れるのだが、
今回はその件で話させていただく。
文字コードとは
まずは、Wikipediaの内容を引用しておこう。
文字コード(もじコード)は、コンピュータ上で文字(キャラクタ)を利用する目的で各文字に割り当てられるバイト表現。
文字コード – Wikipedia
もしくは、バイト表現と文字の対応関係(文字コード体系)のことを指して「文字コード」と呼ぶことも多い。
Wikipediaに書いてある通りコンピューター上では、
文字を扱う際にコンピューターが文字を認識できるよう16進数の識別子が割り振られている。
それが、前者の説明にある各文字に割り当てられたバイト表現であり、
その識別子を対応関係を一覧にしてまとめたものが、後者の説明にある文字コード体系である。
ちなみに、Shift-JISやUTF-8は後者に当たるため今回は文字コード体系の説明になる。
また、文字コードのことをエンコードと呼ぶことがある。
ASCII(アスキー)
文字コードについて
ASCII(アスキー、情報交換用米国標準コード[1]、
ASCII – Wikipedia
英: American Standard Code for Information Interchange)は、
現代英語や西ヨーロッパ言語で使われるラテン文字を中心とした文字コード。
最初期の文字コードで、最も基本的な文字コードとして世界的に普及している。
なお、アスキーアートのアスキーはここからきている。
1バイトしか使用しないため、最大で256文字しか取り扱えない。
(ただし、実際に使用しているのは7ビット分の128文字である。)
そのため、半角英数字と記号、改行やタブ等の特殊記号のみの必要最低限な構成となっている。
また、後述するShift-JISやUTF-8、EUCなど多くの文字コードの原型となっている。
文字コード一覧表は下記リンクを参照してほしい。
http://www3.nit.ac.jp/~tamura/ex2/ascii.html
Shift-JIS(シフトジフ)
文字コードについて
Shift-JISは日本語を含む様々な文字を収録されており、
前身のJIS X 0208(JISコード)を基に策定された文字コードである。
特徴としては半角文字と全角文字が連続して記述することができ、
これは半角文字のバイト表現と全角文字の上位1バイトのバイト表現が被らないようにずらしているためである。
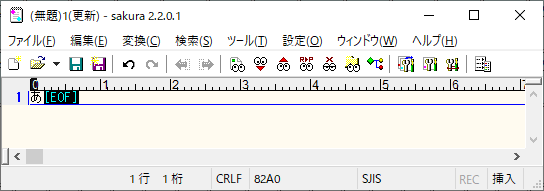
例えば、日本語の”あ”はバイト表現では0x82A0となっているが、
0x82で始まる半角文字が存在しないため、これが全角文字であるとコンピューターが判断できる。
これがShift-JISの利点である。この機能がない文字コードでは、
全角文字を判断するためにエスケープシーケンスと呼ばれる記号で全角文字を囲う必要が出てくる。
日本語環境のWindowsでは標準設定になっているため、意識せずに使用しているユーザは多いだろう。
なお、Windows上ではShift-JISの亜種であるCP932(Windows-31J)となっている。
文字コード一覧表は下記リンクを参照してほしい。
http://charset.7jp.net/sjis.html
なお、歴史や詳細については取り扱う気はないため、
詳細が知りたい方は下記リンクを参照してほしい。
そういったことに詳しいサイトは山のようにあるとだけ言っておこう。
使用時の留意事項
ASCIIをベースにしており、半角英数字の並びはASCIIや後述するUTF-8と同じである。
そのため、ファイルの内容によってはテキストエディタが、
文字コードを勘違いして異なる文字コードで開くことがある。(いわゆる文字化け)
また、半角英数字や半角カナなどが1バイトで表現され、
全角文字(ひらがな、カタカナ、漢字など)は2バイトで表現される。
このことを理解していないとDBに格納した際に、
桁あふれなどでデータが項目内に入りきらないといった事象が発生する。
Unicode(ユニコード)
文字コードについて
Unicode(ユニコード)は、符号化文字集合や文字符号化方式などを定めた、文字コードの業界規格。
Unicode – Wikipedia
文字集合(文字セット)が単一の大規模文字セットであること(「Uni」という名はそれに由来する)などが特徴である。
世界中で使用されている全ての文字を、
共通の文字コードで利用できるようにしようという考えで考案された規格である。
※Unicodeは実際には文字集合なのだがややこしいので割愛
Unicode周りは非常にややこしいが、実のところUnicodeという文字コードは一般的に使用されず、
多くの場合、プログラムの内部でのみ取り扱われる。
実際に目にするのはUnicodeの規格で策定されたUTF-8やUTF-16、UTF-32などである。
規格ないしプロジェクトがUnicodeで、
実際に提供されるサービスがUTF-8、UTF-16、UTF-32などの文字コードといったところだろう。。。
ちなみにUTF-8、UTF-16のように8の倍数になっているが、
これは1バイトが8ビットで構成されているためである。
まあ、IT技術者には愚問な話であろうが。。。
余談だがUTF-8よりUTF-16の方がUnicodeの原型に近いらしい。
なお、使用頻度はお察しの通りである。
使用時の注意事項
Unicode系の文字コードで注意すべき点としては、BOMの有無についてだろう。
例えば、メモ帳などで文字コードがUTF-8のファイルを作成した場合、先頭3バイトにBOMが付く場合がある。
これは符号化方式を識別するためのものらしいが、テキストエディタにも表示されないため、
気付かずに取り扱うとプログラムやソフトウェアの誤作動の原因にもなる。
筆者もこれに気付かず何度か本番機でやらかしたものである。
割とはた迷惑な機能である。。。
なお、JavaやVBAの内部で使用されている言語だったりする。
そのため、Javaで文字コード変換した際は内部上で、
Shift-JIS→Unicode→UTF-8のような順で変換されている。
そのため、同じ文字コードでの変換でも文字化けが起こることがある。
(主に、CP932など文字コードの亜種が原因である。)
また、半角文字も全角文字もすべて2バイトで構成されており、最大で65,536文字取り扱えるが、
全ての文字を2バイトにまとめるのは不可能とのこと。
どう考えても漢字のせいだろう。。。
UTF-8(ユーティーエフエイト)
文字コードについて
UTF-8とは、Unicode/UCSで定義された文字集合を表現することができる文字コード(符号化方式)の一つ。
UTF-8とは – 意味をわかりやすく – IT用語辞典 e-Words
一文字を1~6バイトの可変長で表現するもので、様々な言語の文字を扱える文字コードとしては世界的に最も普及している。
Unicode用の符号化方式のひとつで、世界中で最も使用されている文字コードとされている。
ASCIIコードとの互換性も高く同じ文字コードが高く多くのソフトウェアで用いられる。
XMLやPython、HTMLなどもUTF-8で取り扱うことが多い。
文字コード一覧表は下記リンクを参照してほしい。
https://orange-factory.com/dnf/utf-8.html
使用時の注意事項
ASCIIをベースとしており、半角英数字はShift-JISと変わらない。
そのため、ファイルの内容によってはテキストエディタが文字コードを誤ることがある。
その際はエンコーディングを変更して開きなおすなどの対応をとろう。
また、半角英数字や記号などは1バイトだが、
ひらがな、カタカナ、漢字、半角カナなど日本語はすべて3バイトである。
つまり、Shift-JISとは異なり、実際の文字の大きさがバイト数とイコールではない。
この点は現職のITエンジニアでも誤解している人が多いので特に注意してほしい。
Shift-JISからUTF-8にコード変換した際はファイルサイズにも目を配るといいだろう。
なお、DBに取り込む際も文字コードには要注意である。
DBをUTF-8で作成していた場合、Shift-JISで書かれたデータなどを取り込もうとすると、
日本語文字が3バイトに変換されるためサイズが増大し、項目長内に収まらない事象が発生する。
なお、筆者が経験した例だと、日本語文字と穴埋めで付加されるSPACEがDBの項目長をオーバーし、
どうあがいても対象項目にデータが入らないという馬鹿げた事態も起きた。
その時は項目長を大きめに確保して対処したが、未だに不可解な事象である。
EUCコード(イーユーシーコード)
文字コードについて
EUC-JP(Extended UNIX Code Packed Format for Japanese、日本語EUC)は
EUC-JP – Wikipedia
UNIX上で日本語の文字を扱う場合に利用されてきた文字コード(符号化方式)のひとつである。
UNIX以外のOS上で使われることもある
UNIXやLinux上でよく使用される文字コードで、
Windowsユーザーはほぼ縁がない代物と言っていいかもしれない。
筆者も業務上でLinuxサーバーを見ているが、あまり使用したためしがない。
そもそも、サーバーの文字コードをUTF-8にしているせいだが。。。
文字コード一覧表は下記リンクを参照してほしい。。
http://charset.7jp.net/euc.html
使用上の注意事項
Shift-JISと同様全角文字と半角文字で分かれているが、半角カナは2バイトである。
その点は注意しておいた方がいい。
半角カナ周りは非常にややこしい。
バイト数を節約するつもりかは知らないが、
データ交換の場でよく使用されるのが困りものである。
最後に
以上が基本的な文字コードである。
他にもJISコードや説明にもあったUTF-16やUTF-32、EBCDIC(この中でも各企業ごとに分かれている)
など様々な文字コードがあるが、こちらは別の機会に話したいと思う。
特にEBCDICは色々と悩まされることが多いため、いつか専用の記事を書きたいものである。
やれIBM漢字だの、NEC漢字だの、JEF漢字にEBCDIK(KEISともいう)と好き勝手に作ったせいで、
どのEBCDICコードを使用しているのか担当者もわかってないことが多々ある。
ホント勘弁してほしい。。。
[…] [用語集]文字コードの解説① – 路傍の石なITエンジニアの雑記 (ta-bos… […]