はじめに
どうも、弟に風邪をうつされて喉の痛みと咳に苦しめられたしがないITエンジニアです。
免疫が高すぎるのか低すぎるのか喉以外には全く症状が進行せず、
熱も出ないから本当に風邪だったのかわからない。。。
その状態でも仕事は出来ていたのだが通話となると、
ストレスで防御反応が出て咳が止まらなくなるのは非常に困った。
さて、今回は「Pythonで学ぶはじめてのAIプログラミング 自然言語処理と音声処理」の内容を見ていく。
前回C++で似たようなプログラムを組んだが今回は大本のプログラムである。
書籍のタイトル通りPythonコードで実装されている。

[Python]3-gramの実装
まず初めにこのプログラムはコンソール上でしか実行できない。
というのも実行時にコンソールコマンドでテキストファイルなどを読み込ませる必要があり、
IDE(統合開発環境(Visual Studioなど))などの開発環境ではそれらの設定は難しいためである。
(筆者は知らないが設定次第ではできるかもしれない。)
また、このプログラムを実行するためだけにバッチを作成するのも面倒ということもある。。。
コード
"""
ana3gram.pyプログラム
3-gram出現頻度リストの作成
使い方 c:\>python ana3gram.py < (日本語テキストデータ)
"""
# モジュールのインポート
import sys
import collections
import pprint
# メイン実行部
# 解析対象文字列の読み込み
inputtext = sys.stdin.read()
# 3-gramの生成
ngram = [ ]
for i in range(len(inputtext) - 2):
ngram.append(inputtext[i:i+3])
# 並び替え
c = collections.Counter(ngram)
pprint.pprint(c)
# ana3gram.pyの終わりコードの解説
まず初めに3つほどモジュールのインポートをインポートしている。
sysはインタプリタや実行環境に関するモジュール、collectionsは様々なコンテナのモジュール、
pprintという標準出力のモジュールである。
# モジュールのインポート
import sys
import collections
import pprint 次にメイン部の最初のコマンドだが、sysモジュールの標準入力からの読込処理を使用し、
python実行時に読み込んだテキストデータを取得している。
sys — システムパラメータと関数 — Python 3.10.6 ドキュメント
# 解析対象文字列の読み込み
inputtext = sys.stdin.read() その後、ngramというリストデータを作成し、
for文で3文字ずつ抽出した文字列をリストデータに登録していく。
なお、ループ回数は3-gramで生成される要素数となっている。
# 3-gramの生成
ngram = [ ]
for i in range(len(inputtext) - 2):
ngram.append(inputtext[i:i+3]) 生成した3-gramのデータをcollectionsモジュールのCounterオブジェクトにセットすることで、
同一文字列のサマリーと並び替えを同時に行う。
C++だと手間がかかる工程なのにPythonだとワンライナー。。。
collections — コンテナデータ型 — Python 3.10.6 ドキュメント
# 並び替え
c = collections.Counter(ngram) 最後にpprintによってCounterオブジェクトのデータを整形して標準出力している。
なお、pprintは「pretty-print」の略らしい。。。
Pythonのpprintの使い方(リストや辞書を整形して出力) | note.nkmk.me
pprint.pprint(c)実行結果
あとはコンソール上でPythonファイルの実行時にテキストデータを読み込ませるだけである。
筆者は枕草子の冒頭を抜き出して検証しているが読み込ませる内容な何でもよい。
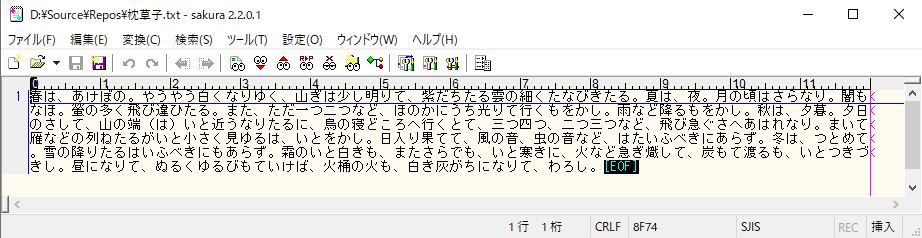
実行結果については下図の通りである。
表示方法を変えたい場合はpprintのパラメータを色々変えてみてほしい。
![[Python]n-gramの実行結果](https://ta-bossweb.com/wp-content/uploads/2022/10/スクリーンショット-2022-10-22-235013.png)
最後に
いかがだっただろうか。
「餅は餅屋」という言葉があるようにプログラム言語も得意とする内容は異なっている。
処理速度を求める場合C++は有用だが、データの取り扱いが難しく実装のハードルが高い。
その点、Pythonはデータの取り扱いが容易なため実装のハードルが低い。
テキスト処理を実装するなら間違いなくPythonの方が向いている。