目次
はじめに
どうも、家族と川遊びやアスレチックを満喫したしがないITエンジニアです。滋賀は自然が多くて良いところ。
川遊びなどのしたのだが、川は流水のため日差しで冷えることがなく冷たかった。
全身を凍えさせながらシュノーケルでアマゴなどの魚の位置を確認したりしたのだが、
魚を見ていると久々に釣りがしたくなった。

さて、今回はテキスト処理の中でも初歩的なn-gramについてやっていく。
参考の書籍は「Pythonで学ぶはじめてのAIプログラミング 自然言語処理と音声処理」である。
書籍の内容は題名の通りPythonで自然言語処理などをやっていくのだが、
今回はC++でn-gramの実装をしていきたいと思う。
(何故C++なのか、単に筆者の趣味である。)

n-gramとは
N-gramとは任意の文字数で文章を分割する手法のことです。
任意の文字数は連続するn個の単語や文字のまとまりを表し、N-gramではnが1の場合、
【自然言語処理】N-gramとは | AI Academy Media
uni-gram(ユニグラム)と呼び、2の場合をbi-gram(バイグラム)、
3の場合をtri-gram(トライグラム)と呼びます。
n-gramのnは、着目する文字の並びの文字数で、例えば、uni-gramでは、
元の文章をばらばらの1文字ずつに分解し、それらの現れ方について解析する。
現れ方の傾向を調べることで、その文章の特徴を探ることができるらしい。
また、uni-gramは1-gram、bi-gramは2-gram、tri-gramは3-gramの別名が存在する。
日本語文章の解析では、n=3とする3-gramがよく用いられる。
これは日本語の単語の長さや、文法の特性に依存している。
ちなみに、n文字の文から3-gramを生成すると、n-2個の3-gramが生成されるとのこと。
予め配列の大きさを決めておきたい場合は参考にするとよい。
また、出来上がった3-gramの集合を3-gram分布という。
この分布から文字列の出現数を解析することで、
その文章で頻出する文字列から何を主張した文章なのか、
あるいは、他の文章と照らし合わせることで文章間の類似性を調べることができる。
3-gramの生成
下図は、とある早口言葉を3-gramで分解した様子である。
3文字ずつ文字列を抽出していく処理を順次行っていく。
先頭文字から順に1文字ずつ開始地点をずらしながら、3文字の抽出が不可能になるまで繰り返す。
そうして、最終的に文章の文字数-2の文字列の集合が生成される。

[C++]3-gramの実装
それでは、実装の方をやっていく。
枕草子の冒頭部分を3-gramで3文字ずつの文字列の配列を生成する。
要素数の確保はvectorで行っており、最初に文章の文字数を -2 した値分要素を確保している。
また、特記事項として通常のstringではなく、wstringを使用している。
アルファベットなど半角文字列だけならstringでも実装可能である。
しかし、日本語など全角文字を使用する場合、
stringでは全角文字一文字あたり二文字分のスペースを消費してしまう。
結果、二文字抽出しなければいけないところを一文字だけ抽出し、
文字がつぶれるといったことがたたあったため、やむを得ずwstringを使用している。
こちらは、全角も半角も同じサイズ分確保するため、
文字列を抽出した際に文字がつぶれることがない。
まず間違いなく、マルチバイト文字、ワイド文字などの概念が関係してくるのだと思う。
普段意識しないのにこうゆう時に限ってしゃしゃり出てくるのだから困りものである。。。
コード
// 3-gram
//
#include <iostream>
#include <string>
#include <vector>
using namespace std;
int main()
{
const int N = 3;
// 全角、半角双方を正しく抽出するためwstringを使用
// wstringについてはリファレンスを参照:https://cpprefjp.github.io/reference/string/basic_string.html)
// sringの内容は枕草子(https://www.bou-tou.net/makuranososhi/)
const wstring str = L"春は、あけぼの。やうやう白くなりゆく、山ぎは少し明りて、紫だちたる雲の細くたなびきたる。"
L"夏は、夜。月の頃はさらなり。闇もなほ。螢の多く飛び違ひたる。また、ただ一つ二つなど、ほのかにうち光りて行くもをかし。雨など降るもをかし。"
L"秋は、夕暮。夕日のさして、山の端(は)いと近うなりたるに、烏の寝どころへ行くとて、三つ四つ、二つ三つなど、飛び急ぐさへあはれなり。まいて雁などの列ねたるがいと小さく見ゆるは、いとをかし。日入り果てて、風の音、虫の音など、はたいふべきにあらず。"
L"冬は、つとめて。雪の降りたるはいふべきにもあらず。霜のいと白きも、またさらでも、いと寒きに、火など急ぎ熾して、炭もて渡るも、いとつきづきし。昼になりて、ぬるくゆるびもていけば、火桶の火も、白き灰がちになりて、わろし。";
vector<wstring> result(str.length() - 2); // 3-gram で生成される要素数は文章を N とした場合、N - 2 個生成される。
cout << "生成される3-gramの要素数は" << str.length() - 2 << endl;
for (int i = 0; i + N - 1 < str.length(); ++i)
{
// 文字列を抽出し、vectorに追加
//substrについてはリファレンスを参照:https://cpprefjp.github.io/reference/string/basic_string/substr.html)
//result.push_back(str.substr(i, N));
result[i] = str.substr(i, N);
}
wcout.imbue(locale("Japanese")); // ロケールを日本語に変更(参考:https://qiita.com/toris-birds/items/5443777ad0bb0ae05d3b)
for (const auto& s : result)
{
wcout << s << endl;
}
cout << "生成された要素数:" << result.size() << endl;実行結果
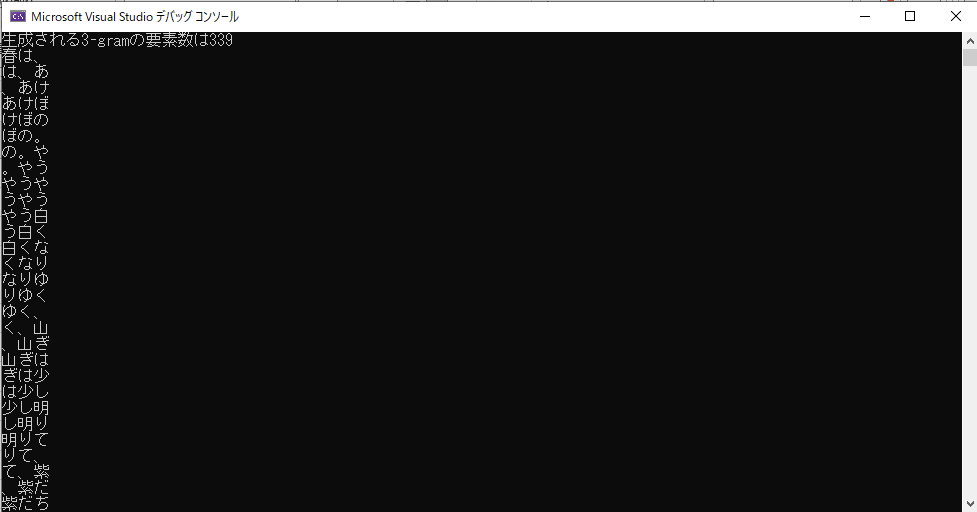

文章が長すぎるせいで全部移しきれないのは完全に失策である。
調子に乗って文章を長くし過ぎた。。。
最後に
取り敢えず今回の内容は以上である。
文章の添削や説明が足りていない部分については多々あるため随時埋めていく。
そのうち、n-gram分布の解析などにも手を出していきたいが、
生憎準備不足、勉強不足なので次回に持ち越しとする。
おまけ
おまけとして、今回見本で作成したExcelの内容を解説していこうと思う。
文字数の取得
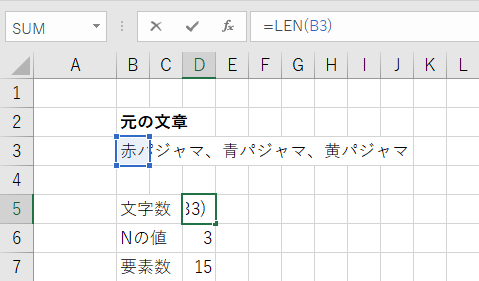
文字数を値はLEN関数で取ってきている。
なお、LEN関数は文字数を取得する関数である。
類似関数にLENB関数があるがあちらはバイト数である。
余談だがVBAにもほぼ同名の関数があり、基本的にLenB関数は要らない子である。
(VBA内のエンコードはUnicode (UTF-16)のため、文字列は全て2バイト)
頑張ったら活かせるがかなり手間
要素数の計算
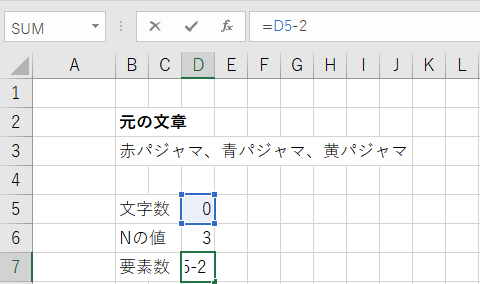
要素数は上記で求めた文字数を-2した値である。
おそらくはNの値-1にした方が正しいと思われるが、
説明用のためそこまで作りこんでない。
文字列の分解
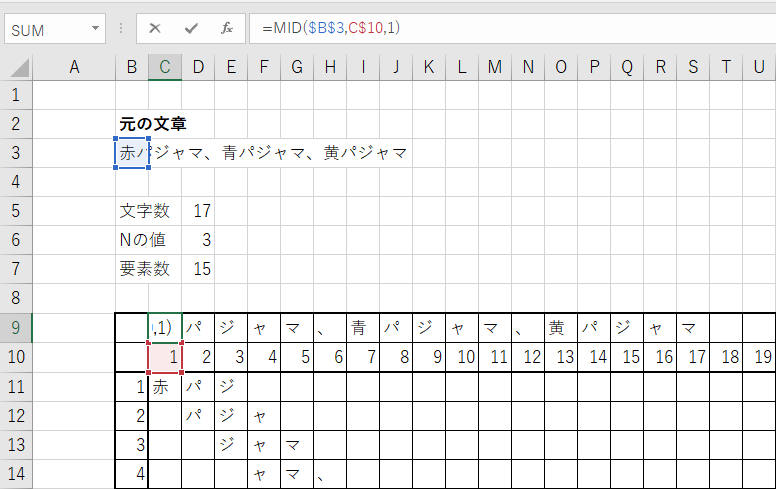
セルC9~U9では元の文章からそれぞれ1文字ずつ抽出しているが、
こちらはMID関数によって抽出している。
MID関数は第一パラメータに抽出対象の文字列で元の文章を指定している。
第二パラメータが抽出位置で、セルC9ではセルC10を指定している。
なお、10に$がついており10行なのは固定。
第三パラメータが抽出する文字数で、今回は1文字だけ抽出したいため1をセットしている。
Excelでの3-gramの構築
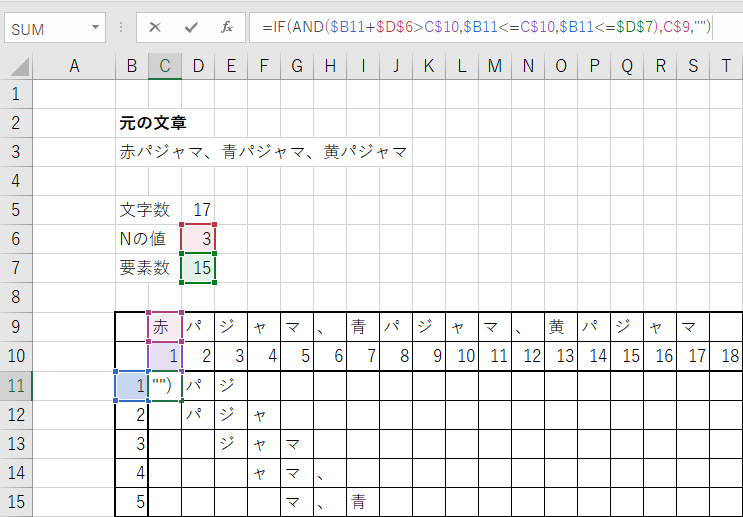
最後にExcelで3-gramを構築する場合はIF文により実装することができる。
IF文は第一パラメータに条件、第二パラメータに真の時の処理、
第三パラメータに偽の時の処理を書く。
一つ目の条件だが、$B11+$D$6 > C$10 のうち、
$B11は縦の列でこれらC++の例でいうと要素数や i に相当する。
Bに$がついておりB列は固定である。
そして、$D$6はNの値、C$10は文字ごとに採番した値のため、
セルと同じ列の文字が抽出対象かどうかを検査している。
二つ目の条件は、$B11 <= C$10 は、
一つ目の条件からさらに条件を絞り込むための条件である。
一つ目の条件だけの場合、
セルC12でも”赤”という文字を抽出してしまうためそれを抑制する。
三つ目の条件は、$B11 <= $D$7 となっている。
これは要素数の範囲内でのみ文字を抽出する条件である。
以上がExcelの解説である。
本当はExcelの資料を添付したかったが方法がわからないので諦めた。
2022/10/22 追記
改めて考えるとvectorに格納するより、
mapに格納する方が色々使い勝手がいいことに気付いたので書いてみる。
コード
// 3-gram
//
#include <iostream>
#include <string>
#include <utility>
#include <map>
#include <queue>
using namespace std;
int main()
{
const int N = 3;
// 全角、半角双方を正しく抽出するためwstringを使用
// wstringについてはリファレンスを参照:https://cpprefjp.github.io/reference/string/basic_string.html)
// sringの内容は枕草子(https://www.bou-tou.net/makuranososhi/)
const wstring str = L"春は、あけぼの。やうやう白くなりゆく、山ぎは少し明りて、紫だちたる雲の細くたなびきたる。"
L"夏は、夜。月の頃はさらなり。闇もなほ。螢の多く飛び違ひたる。また、ただ一つ二つなど、ほのかにうち光りて行くもをかし。雨など降るもをかし。"
L"秋は、夕暮。夕日のさして、山の端(は)いと近うなりたるに、烏の寝どころへ行くとて、三つ四つ、二つ三つなど、飛び急ぐさへあはれなり。まいて雁などの列ねたるがいと小さく見ゆるは、いとをかし。日入り果てて、風の音、虫の音など、はたいふべきにあらず。"
L"冬は、つとめて。雪の降りたるはいふべきにもあらず。霜のいと白きも、またさらでも、いと寒きに、火など急ぎ熾して、炭もて渡るも、いとつきづきし。昼になりて、ぬるくゆるびもていけば、火桶の火も、白き灰がちになりて、わろし。";
map<wstring, int> result = {}; // mapにすることでカウントアップが楽になる
cout << "生成される3-gramの要素数は" << str.length() - 2 << endl;
for (int i = 0; i < str.length() - 2; ++i)
{
result[str.substr(i, N)] = result[str.substr(i, N)] + 1; // mapに登録とカウントアップを行う
}
wcout.imbue(locale("Japanese")); // ロケールを日本語に変更(参考:https://qiita.com/toris-birds/items/5443777ad0bb0ae05d3b)
cout << "生成された要素数:" << result.size() << endl;
// 優先度キューの並び替えに使用
auto compare = [](const auto& a, const auto& b)
{
return a.second < b.second;
};
// 優先度付きキューで並び替え
priority_queue <
pair<wstring, int>,
vector<pair<wstring, int>>,
decltype(compare)
> que {compare};
// キューにペアを登録
for (const auto& m : result)
{
que.push(m);
}
// キューの先頭から順に出力
while (!que.empty())
{
const auto& m = que.top();
wcout << m.first << ", " << m.second << endl;
que.pop();
}
return 0;
} mapを使用することで要素への登録と同一文字のカウントアップを同時に出来るようになっている。
その後、優先度付きキューに登録しなおすことで並び替えをしている。
※map関数ではソートが上手く動作しない
ちなみに、sort関数でもやりようによってはソートできるらしいが、
どのみちややこしいコードを書かないといけないので今回はやらない。
ソート方法については以下のリンクが参考になるだろう。
C++ で値でマップを並べ替える | Delft スタック (delftstack.com)
実行結果

実行結果で分かる通り、カウントアップと数値が大きい順に並び替えられていることがわかる。
Pythonだともっと短いコードにまとめられるのだが、C++はどうもテキスト処理が苦手なようである。
追記でやりたいことまでやれたことに満足である。
本書のPythonによる正式なコードもどこかのタイミングで記事にしたいものである。